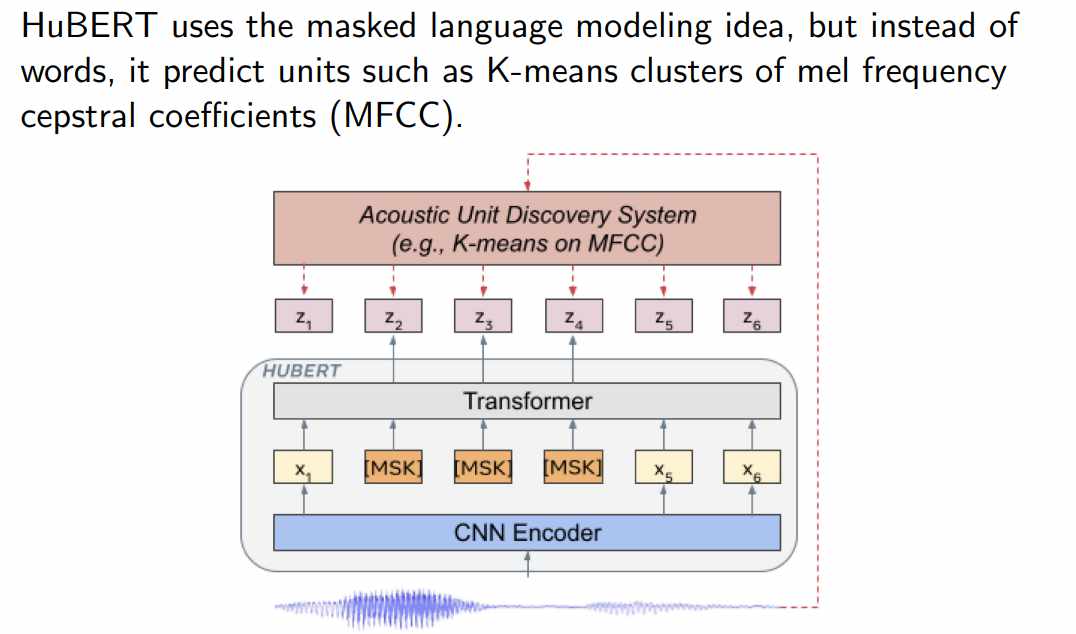
Mau pakai MFCC atau Wav2Vec?
Mau pakai MFCC atau Wav2Vec? Kalimat tersebut tampaknya mengacu pada keraguan dalam memilih antara dua metode atau teknik untuk analisis suara atau pengenalan suara, yaitu MFCC (Mel Frequency Cepstral Coefficients) dan Wav2Vec. Kedua metode ini sering digunakan untuk tugas pemrosesan sinyal audio, tetapi memiliki pendekatan yang sangat berbeda. Mari kita bahas lebih lanjut:
1. MFCC (Mel Frequency Cepstral Coefficients)
- Apa itu: MFCC adalah metode ekstraksi fitur yang sudah lama digunakan dalam speech recognition. Teknik ini bekerja dengan mengubah sinyal audio menjadi representasi fitur yang lebih ringkas dengan memodelkan karakteristik frekuensi suara manusia.
- Kelebihan:
- Sangat stabil dan sering digunakan dalam berbagai aplikasi pengenalan suara klasik.
- Dapat memberikan hasil yang andal pada berbagai aplikasi, terutama untuk model machine learning tradisional seperti HMM (Hidden Markov Models) dan SVM.
- Keterbatasan:
- Cenderung kurang efisien ketika dihadapkan pada data suara yang lebih kompleks atau variabilitas yang tinggi, seperti aksen yang berbeda, kebisingan, atau konteks penggunaan yang lebih dinamis.
- Tidak memanfaatkan keuntungan dari perkembangan model deep learning terbaru.
2. Wav2Vec
- Apa itu: Wav2Vec adalah model yang lebih baru berbasis deep learning yang dikembangkan oleh Facebook AI Research. Model ini belajar representasi audio secara langsung dari data mentah tanpa ekstraksi fitur tradisional (seperti MFCC).
- Kelebihan:
- Memanfaatkan pendekatan unsupervised learning dan self-supervised learning untuk belajar langsung dari data suara mentah, sehingga lebih mampu menangkap fitur-fitur yang lebih kompleks dan beragam dalam audio.
- Lebih adaptif dan mampu menghadapi tantangan baru seperti suara yang bervariasi, aksen yang berbeda, atau data yang lebih sulit untuk diolah dengan metode tradisional.
- Memberikan peluang untuk keterbaruan (innovation potential) dalam penelitian atau aplikasi pengenalan suara, karena memanfaatkan teknologi terkini.
- Keterbatasan:
- Membutuhkan komputasi yang lebih tinggi, baik dari segi waktu pelatihan maupun dari segi memori.
- Terkadang membutuhkan dataset yang lebih besar agar dapat berfungsi optimal.
Interpretasi “Peluang Keterbaruan”
Ungkapan “lebih banyak mendapatkan peluang keterbaruan” mengindikasikan bahwa Wav2Vec mungkin dianggap sebagai teknik yang lebih modern dan berpotensi menghadirkan inovasi baru atau solusi yang lebih canggih dibandingkan MFCC. Dengan Wav2Vec, peluang untuk menangani tugas-tugas pengolahan suara yang lebih rumit atau memanfaatkan model AI yang lebih baru akan lebih besar, sementara MFCC lebih bersifat “tradisional” dan stabil, namun mungkin kurang inovatif dalam konteks tantangan atau fitur baru yang muncul.
Mau pakai MFCC atau Wav2Vec? kemungkinan mempertimbangkan apakah akan tetap menggunakan MFCC, yang sudah mapan dan banyak digunakan, atau beralih ke Wav2Vec, yang lebih inovatif dan memiliki potensi lebih besar untuk menangani data atau fitur suara yang lebih kompleks dengan pendekatan deep learning. Pilihan ini akan tergantung pada kebutuhan aplikasi dan sumber daya komputasi yang tersedia.
Sumber Image : https://courses.grainger.illinois.edu/ece537/fa2022/slides/lec25.pdf